

W3C XProc is a specification that defines a processor for working with XML technologies. eXist XProc implementation is called xprocxq and is mostly developed in XQuery.
Using XProc's core, standard, optional and extension steps one defines XML pipelines which can model a wide range of processes.
Steps accept input XML and produce output XML, its in this manner (somewhat analogous to unix pipes) that you can orchestrate and create sophisticated XML workflows.
Since eXist v1.3/1.4, xprocxq is built and configured by default and should be enabled and ready to use.
Check out some simple examples to check if your eXist is working.
The following XQuery file is an example of how to run xprocxq from within eXist.
xquery version "1.0" encoding "UTF-8";
(: for now you need to declare these namespaces :)
import module namespace const = "http://xproc.net/xproc/const";
import module namespace xproc = "http://xproc.net/xproc";
import module namespace u = "http://xproc.net/xproc/util";
(: define standard input source binding :)
let $stdin :=document{<test>Hello World</test>}
(: the xproc pipeline :)
let $pipeline :=document{
<p:pipeline name="pipeline"
xmlns:p="http://www.w3.org/ns/xproc">
<p:identity/>
</p:pipeline>
}
return
(: the xproc entry function :)
xproc:run($pipeline,$stdin)
list and define all xproc entry functions
The result of running this xquery should resemble:
<test>Hello World</test>
At their simplest, XProc pipelines contain steps, each of which accept zero or more XML documents as their input and produce zero or more XML documents as output.
The XProc code in the following listing consists of a <p:pipeline> top-level element, a <p:xslt> step, and not much else.
<p:declare-step xmlns:p="http://www.w3.org/ns/xproc" name="simple-pipeline">
<p:input port="source" primary="true" sequence="false"/>
<p:output port="result" primary="true" sequence="false"/>
<p:xslt name="step1">
<p:input port="source">
<p:pipe step="simple-pipeline" port="source"/>
</p:input>
<p:input port="stylesheet">
<p:document href="/db/xproc/examples/stylesheet.xml"/>
</p:input>
</p:xslt>
</p:declare-step>
An XML document is brought in as standard input using the stdin url param. The XProc processor uses this XML document as the input to the first step, <p:xslt> step, which applies an XSLT process using stylesheet.xml.
As the pipeline contains only a single step, results of XSLT processing are placed onto the result port for the pipeline, providing the XML document to standard output. The following figure illustrates this process, outlining where the XML document flows from source and result ports.
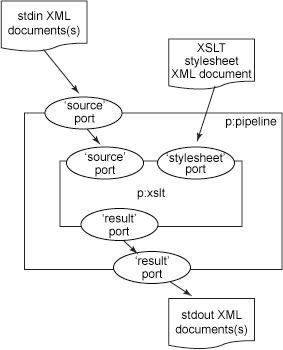
In the Simple Pipeline listing, I used <p:pipeline>, which implicitly declared a source input and result output port. Using <p:declare-step> now means that I have to explicitly define these ports as well as declare step bindings between sequential sibling steps. These bindings and ports are summarized below:
<p:pipeline xmlns:p="http://www.w3.org/ns/xproc" xmlns:c="http://www.w3.org/ns/xproc-step" name="pipeline">
<p:compare name="compare"> (: compare test step :)
<p:input port="alternate">
<p:document href="/db/xproc/test.xml"/> (: example of using p:document :)
</p:input>
</p:compare>
<p:choose name="mychoosestep">
<p:when test=".//c:result[.='false']"> (: note the eXist specific path convention with root :)
<p:identity>
<p:input port="source">
<p:inline>
<p>This pipeline failed.</p>
</p:inline>
</p:input>
</p:identity>
</p:when>
<p:when test=".//c:result[.='true']"> (: success :)
<p:identity>
<p:input port="source">
<p:inline>
<p>This pipeline successfully processed.</p>
</p:inline>
</p:input>
</p:identity>
</p:when>
<p:otherwise>
<p:identity>
<p:input port="source">
<p:inline>
<p>This pipeline failed.</p>
</p:inline>
</p:input>
</p:identity>
</p:otherwise>
</p:choose>
<p:identity> (: currently need to define p:step to get multi container step output :)
<p:input port="source">
<p:step port="result" step="mychoosestep"/>
</p:input>
</p:identity>
</p:pipeline>
This pipeline roughly translates to the following:
xml:base attributes
on elements.
c:param-set XML
document in the result output.
Implementation specific steps
eXist XProc implementation provides a range of extension mechanisms for creating new steps.
The following links run xprocxq against W3C XProc Unit Test suite
Please note that you will need to enable the File extension module and download the W3C XProc test suite to run these tests.
By default, XProc is set to read files only from the XML Database. If you want to access files from the hard drive then you will need to enable eXist File extension module and make sure to use file:// prefix in your file paths.
Initially, development of eXist XProc processor was a standalone project, called xprocxq. The i
xprocxq, being implemented in XQuery, currently has several limitations and is no where compliant with the existing XProc draft specification. The best way to understand what works or doesn't currently is to check out step examples included in the release.
Here is a list of the more severe limitations:
XQuery's somewhat functional approach appealed to me and having been a long time XSLT user I wanted to gain some understanding of the nuances between XSLT and XQuery.
In building xprocxq, my primary goals were;
I think that most people will find using XProc with XQuery is a powerful combination which can be used to implement a wide range of server side applications.
